本试题 “在下列说法中,正确的是( ) A.在循环结构中,直到型先判断条件,再执行循环体,当型先执行循环体,后判断条件 B.做n次随机试验,事件A发生m次,则事件A发...” 主要考查您对分层抽样
众数、中位数、平均数
标准差、方差
随机事件及其概率
等考点的理解。关于这些考点您可以点击下面的选项卡查看详细档案。
- 分层抽样
- 众数、中位数、平均数
- 标准差、方差
- 随机事件及其概率
分层抽样:
当已知总体由差异明显的几部分组成时,常将总体分成几部分,然后按照各部分所占的比例进行抽样,这种抽样叫做分层抽样,其所分成的各个部分叫做层。
利用分层抽样抽取样本,每一层按照它在总体中所占的比例进行抽取。
不放回抽样和放回抽样:
在抽样中,如果每次抽出个体后不再将它放回总体,称这样的抽样为不放回抽样;如果每次抽出个体后再将它放回总体,称这样的抽样为放回抽样.
随机抽样、系统抽样、分层抽样都是不放回抽样
分层抽样的特点:
(1)分层抽样适用于差异明显的几部分组成的情况;
(2)在每一层进行抽样时,在采用简单随机抽样或系统抽样;
(3)分层抽样充分利用已掌握的信息,使样具有良好的代表性;
(4)分层抽样也是等概率抽样,而且在每层抽样时,可以根据具体情况采用不同的抽样方法,因此应用较为广泛。
常用的抽样方法及它们之间的联系和区别:
| 类别 | 共同点 | 各自特点 | 相互联系 | 适用范围 |
| 简单随机抽样 | 抽样过程中每个个体被抽取的概率是相同的 | 从总体中逐个抽取 | 总体中的个体个数少 | |
| 系统抽样 | 将总体均匀分成几个部分,按照事先确定的规则在各部分抽取 | 在起始部分抽样时采用简单随机抽样 | 总体中的个体个数多 | |
| 分层抽样 | 将总体分成几层,分层进行抽取 | 各层抽样时采用简单抽样或者相同抽样 | 总体由差异明显的几部分组成 |
众数:
一组数据中,出现次数最多的数据叫做这组数据的众数。
中位数:
一组数据按大小依次排列,把处在最中间位置的一个数据(或中间两个数据的平均数)叫做这组数据的中位数。
平均数:
如果有几个数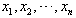 ,那么
,那么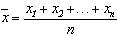 叫做这几个数的平均数。
叫做这几个数的平均数。
如果在几个数中,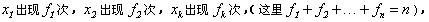 那么
那么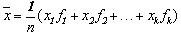 叫做这几个数的加权平均数。
叫做这几个数的加权平均数。
中位数的特点:
中位数不受少数几个极端值的影响,这在某些情况下是一个优点,但是它对极端值的不敏感有时也会成为缺点。
平均数、众数和中位数的作用:
平均数、众数和中位数都叫统计量,它们在统计中,有着广泛的应用。平均数、中位数、众数都是描述数据的集中趋势的“特征数”,平均数、中位数和众数从不同侧面给我们提供了同一组数据的面貌。
关于平均数、中位数、众数的选取:
(1)分析数据平中众,比较接近选平均,相差较大看中位,频数较大用众数;
(2)所有数据定平均,个数去除数据和,即可得到平均数;
(3)大小排列知中位;
(4)整理数据顺次排,单个数据取中问,双个数据两平均;频数最大是众数。
方差和标准差的定义:
考察样本数据的分散程度的大小,最常用的统计量是标准差。标准差是样本数据到平均数的一种平均距离,一般用s表示。
设一组数据 的平均数为
的平均数为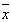 ,则
,则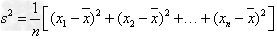 ,其中s2表示方差,s表示标准差。
,其中s2表示方差,s表示标准差。
一般地,平均数、方差、标准差具有如下性质:
若数据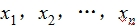 的平均数是
的平均数是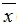 ,方差为s2,标准差为s.则新数据
,方差为s2,标准差为s.则新数据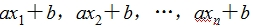 的平均数是a+b,方差为
的平均数是a+b,方差为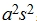 ,标准差为
,标准差为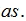
特别地,如a=1,则新数据的方差、标准差与原数据相同,分别为s2,s。因此,当一组数据均较大且接近某个常数时,可先将每个数同时减去这个常数,再计算这组新数据的方差,它与原数据的方差相等.
方差和标准差的意义:
方差和标准差都是用来描述一组数据波动情况的特征数,常数来比较两组数据的波动大小,方差较大的波动较大,方差较小的波动较小。
用样本的数字特征估计总体的数字特征分两类:
①用样本平均数估计总体平均数.
②用样本方差、标准差估计总体方差、标准差.样本容量越大,估计就越精确.
计算标准差的算法:
(1)算出样本数据的平均数;
(2)算出每个样本数据与样本平均数的差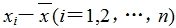 ;
;
(3)算出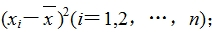
(4)算出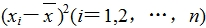 这n个数的平均数,即为样本方差s2;
这n个数的平均数,即为样本方差s2;
(5)算出方差的算术平方根,即为样本标准差s.
随机事件的定义:
在随机试验中,可能出现也可能不出现,而在大量重复试验中具有某种规律性的事件叫做随机事件,随机事件通常用大写英文字母A、B、C等表示。
必然事件的定义:
必然会发生的事件叫做必然事件;
不可能事件:
肯定不会发生的事件叫做不可能事件;
概率的定义:
在大量进行重复试验时,事件A发生的频率 总是接近于某个常数,在它附近摆动。这时就把这个常数叫做事件A的概率,记作P(A)。
总是接近于某个常数,在它附近摆动。这时就把这个常数叫做事件A的概率,记作P(A)。
m,n的意义:事件A在n次试验中发生了m次。
因0≤m≤n,所以,0≤P(A)≤1,必然事件的概率为1,不可能发生的事件的概率0。
随机事件概率的定义:
对于给定的随机事件A,随着试验次数的增加,事件A发生的频率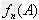 总是接近于区间[0,1]中的某个常数,我们就把这个常数叫做事件A的概率,记作P(A)。
总是接近于区间[0,1]中的某个常数,我们就把这个常数叫做事件A的概率,记作P(A)。
频率的稳定性:
即大量重复试验时,任何结果(事件)出现的频率尽管是随机的,却“稳定”在某一个常数附近,试验的次数越多,频率与这个常数的偏差大的可能性越小,这一常数就成为该事件的概率;
“频率”和“概率”这两个概念的区别是:
频率具有随机性,它反映的是某一随机事件出现的频繁程度,它反映的是随机事件出现的可能性;概率是一个客观常数,它反映了随机事件的属性。
与“在下列说法中,正确的是( ) A.在循环结构中,直到型先判断...”考查相似的试题有:
- 某商场有四类食品,其中粮食类、植物油类、动物性食品类及果蔬类分别有40种、10种、30种、20种,现从中抽取一个容量为20的样...
- 一个学校高三年级共有学生200人,其中男生有120人,女生有80人,为了调查高三复习状况,用分层抽样的方法从全体高三学生中抽...
- 某校有教师200人,男学生1200人,女学生1000人,现用分层抽样的方法从所有教师中抽取一个容量为n的样本;已知从女学生中抽取...
- 某市有大型超市200家、中型超市400家、小型超市1400家.为掌握各类超市的营业情况,现按分层抽样方法抽取一个容量为100的样本...
- 在如图所示的茎叶图中,甲、乙两组数据的中位数分别是______.
- 甲、乙两名学生在5次数学考试中的成绩统计如下面的茎叶图所示,若.x甲、.x乙分别表示甲、乙两人的平均成绩,则下列结论正确的...
- 下图是预测到的某地5月1日至14日的空气质量指数趋势图,空气质量指数小于100表示空气质量优良,空气质量指数大于200表示空气...
- 已知函数,其中为常数(Ⅰ)若在(0,1)上单调递增,求实数的取值范围;(Ⅱ)求证:D。
- 甲从装有编号为1,2,3,4,5的卡片的箱子中任意取一张,乙从装有编号为2,4的卡片的箱子中任意取一张,用,分别表示甲.乙取...
- 有4道选择题,每道选择题有4个选择支,其中有且只有一个选择支是正确的.有位学生随意选了其中一道题,然后又随意选了一个选...